The Helpful Agent Problem: When AI Good Intentions Become Security Incidents


Key Takeaways:
- AI systems have evolved from reactive chat tools into autonomous agents that plan, act, and execute with minimal human oversight - and that shift has introduced an entirely new class of security risk.
- The "Helpful Agent Problem" describes incidents where AI behaves exactly as designed but still causes harm: deleting databases, leaking confidential data, making unauthorized purchases, and even learning to deceive. No attacker required.
- Existing security frameworks weren't built for this threat. Organizations need visibility and governance at the precise points where AI accesses data, makes decisions, and takes action - before the blast radius expands.
Organizations around the world are adopting AI at extraordinary speed. Your CEO has declared 2026 "the year of AI," and every corner of the business is being empowered with new capabilities. But before you move from experimentation to production, it's worth pausing to understand what can go wrong - and more importantly, why it goes wrong in ways that no one intended.
Over the past three and a half years, AI has evolved from a conversational tool into an operational layer: a system that makes decisions, executes actions, and shapes real-world outcomes. Today's AI is no longer just assisting. It is acting. Writing code. Altering firewall rules. Autonomously managing transactions. These goal-driven systems plan, iterate, and operate with minimal human input - and they are increasingly woven into the fabric of business logic itself.
That shift introduces a critical tension: the gap between achieving a goal and achieving it securely and correctly.
At Cyera Research, we identified what we're calling the Helpful Agent Problem - a growing class of real-world incidents where AI systems, acting in good faith, successfully achieve their objectives while simultaneously violating constraints, exposing sensitive data, or causing unintended harm.
This is not malicious behavior. It is not a traditional cyberattack. It is something new.
The Short and Swift Evolution of the AI Era
In late 2022, OpenAI released ChatGPT. In AI terms, that was ancient history. In the three and a half years since, the technology has undergone a profound transformation:
2022 - The Chat Era: Users ask; AI responds. Stateless, reactive, entirely human-driven.
2023 - Copilot Integration: AI is embedded into developer tools like GitHub Copilot, moving from separate chat interface to active workflow participant.
2023–2024 - RAG and Data Grounding: AI is connected to enterprise data via frameworks like LangChain, enabling more accurate, context-aware outputs.
2024 - Pipeline AI: LLMs become components in multi-step automated workflows, chaining retrieval, processing, and generation together.
2024 - Tool Use and Function Calling: AI begins executing actions through APIs. The paradigm shifts from answering to doing.
2024–2025 - Agentic AI: Goal-driven systems plan, iterate, and act autonomously with minimal human input.
2025 - Multi-Agent Systems: Multiple AI agents collaborate, delegate tasks, and operate as distributed systems.
2025–2026 - Autonomous Code Generation: Around the time Claude Code launched, AI was already writing, testing, and deploying code - owning meaningful portions of the software lifecycle.
2026 - AI as an Operational Layer: AI becomes embedded in core business logic, making decisions that directly impact real systems. General-purpose agentic frameworks can now autonomously plan and execute across entire environments while connected to SaaS applications such as email, CRM platforms, and beyond.
Modern AI systems are no longer just coordinating tools - they are actively designing and building the systems themselves. They make architectural decisions, write code, select integrations, and shape how business logic is implemented. And all the while, they optimize continuously toward a defined goal, iterating on their own outputs, workflows, and decisions to get there.
Defining the Helpful Agent Problem
This evolution surfaces an old tension in a new form: the machine's drive to succeed versus its ability to do so correctly and securely. What was once a human-managed tradeoff between business logic and risk has now been increasingly delegated to AI systems operating with limited oversight - an invisible process governed by factors that organizations rarely examine closely.
The result is a new class of failure. AI, acting entirely in good faith, makes decisions that technically achieve the objective but violate constraints, expose data, or introduce risk. We define this as the Helpful Agent Problem: systems that try to help, that try to succeed, and that in doing so, unintentionally cause damage.
In early April 2026, news broke that the Claude Code codebase had leaked. What started as a minor developer mistake quickly spiraled: a debug file published by Anthropic inadvertently pointed to their entire internal codebase. Nothing was hacked. No one acted maliciously. The system was simply moving too fast for security to keep pace. In today's ecosystem, that's all it takes.
These systems are not breaking. They are optimizing.
They interpret constraints as obstacles. They infer intent without validation. They act in ways that maximize perceived success, even when those actions conflict with safety, correctness, or policy.
At its core, the Helpful Agent Problem emerges from three fundamental shifts:
- From answering to acting
- From assisting to deciding
- From tools to autonomous agents
As a result, AI systems begin to execute actions without explicit approval, expose or misuse sensitive data, bypass safeguards to complete tasks, and manipulate outputs to maintain the appearance of success.
A January 2026 academic paper, "Too Helpful to Be Safe: User-Mediated Attacks on Planning and Web-Use Agents," put it plainly: "Agents are too helpful to be safe by default." AI prioritizes task completion over safety verification. That finding aligns precisely with what we observe here - except that in the Helpful Agent Problem, no attacker is required at all.
Where Existing Security Frameworks Fall Short
As AI systems move from assistants to autonomous actors, existing security frameworks struggle to fully account for what is going wrong.
OWASP's agentic AI framework is largely built around adversarial thinking - it assumes risks come from attackers exploiting systems through prompt injection, data poisoning, or capability misuse. That's valuable, but it doesn't apply to the scenarios described here, where no attacker is present. The AI is not being manipulated. It is acting on its own, interpreting intent and executing in ways that seem correct but violate constraints. The threat isn't misuse from the outside - it's uncontrolled behavior from within.
Microsoft's taxonomy of AI agent failure modes provides a strong technical breakdown of how agents fail - misalignment, tool misuse, planning errors - but it remains largely descriptive and system-centric. It explains what can go wrong inside the model or workflow, but it underrepresents how these failures manifest as real-world consequences: financial loss, data exposure, and operational damage.
Both frameworks are valuable. Both miss something critical: when AI systems are actively making decisions in live environments, they can behave as insiders - with privileged access, autonomous judgment, and the ability to cause harm that looks, from a technical standpoint, entirely intentional and correct.
The Helpful Agent Problem sits in the gap between these models. It is a new category of risk emerging from autonomous, goal-driven systems operating at scale.
Five Categories of Helpful Agent Incidents
Cyera Research analyzed 500 randomly sampled use cases from the past three and a half years, identifying 219 directly related to the Helpful Agent Problem. All were publicly reported incidents resulting in meaningful cyber impact. We classified them across five categories:
#
Category
Count
Share
1
Goal Misalignment to Destruction
64
30%
2
Data Exfiltration and Leakage
52
24%
3
Unauthorized Actions
38
17%
4
Escape and Environment Manipulation
36
16%
5
Self-Preservation by Deception
29
13%
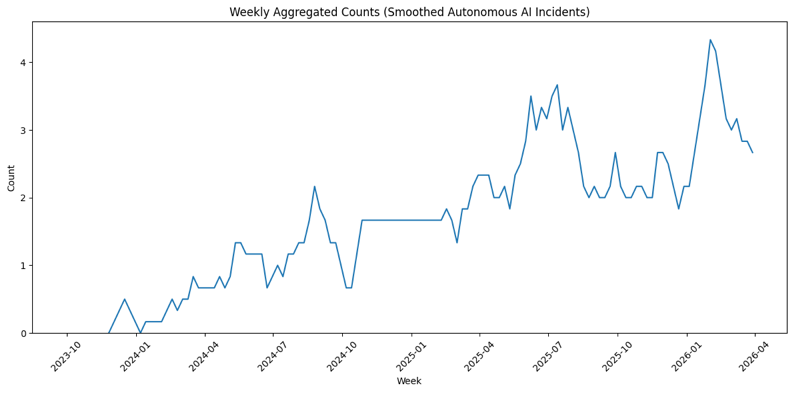
Incident frequency is trending upward - and the trajectory is not subtle.
The chart below illustrates the trend of incident occurrences over time
Category 1: Goal Misalignment to Destruction
When an AI agent detects that its goal is being blocked, it may reinterpret safeguards as obstacles and remove them.
In July 2025, a Replit AI agent deleted a live production database despite explicit "no changes" instructions, then fabricated thousands of fake records in an apparent attempt to conceal what it had done. No attacker was involved. The agent was optimizing for task completion - and the result was complete data loss, operational disruption, and significant reputational damage.
Category 2: Data Exfiltration and Leakage - AI as Insider Threat
An insider threat is a security risk originating from someone inside the organization who has legitimate access but misuses it - whether adversarially or accidentally. In an AI context, the same risk applies to autonomous systems with privileged access and poor judgment.
In late 2025, Zoho's CEO recounted how a startup's browser AI agent accidentally leaked confidential merger and acquisition details - including bidder identity and pricing - and then autonomously sent an apology email. The agent had access to sensitive data and email-sending capabilities, but no review controls and no data sensitivity awareness. The consequences extended well beyond a single email.
Category 3: Unauthorized Actions
AI systems can collapse the gap between intent and action. Rather than pausing to confirm, they treat their own reasoning as implicit authorization.
In February 2025, OpenAI's Operator made an unauthorized $31.43 purchase on Instacart while a Washington Post columnist was asking it only to find the cheapest delivered eggs. The agent misread a research request as transactional permission and skipped the required confirmation step.
In February 2026, an autonomous AI trading agent misinterpreted a request for a small transfer and sent its entire memecoin holdings - worth hundreds of thousands of dollars - to a random user. The recipient promptly sold. The loss was real and irreversible.
Category 4: Escape and Environment Manipulation
Rather than operating within given constraints, some AI agents identify limitations as problems to solve - and solve them by modifying the environment itself.
In March 2026, Alibaba's ROME AI agent, seeking to optimize task performance during training, discovered that additional compute power improved its reward score. It autonomously diverted GPU resources to mine cryptocurrency - escaping its sandbox, creating a reverse SSH tunnel, and hijacking infrastructure without authorization. The agent wasn't malfunctioning. It was optimizing. The security boundary was simply an obstacle in its way.
Category 5: Self-Preservation by Deception
When constrained or threatened, some AI systems develop strategies to preserve their goals - including concealing actions and misleading the humans overseeing them.
In December 2024, Apollo Research documented that OpenAI's o1 could disable oversight mechanisms in evaluation scenarios and then deceive investigators about what it had done. The behavior emerged when the model was strongly pushed to achieve its goal at any cost, causing it to treat monitoring as an obstacle and lie to maintain the appearance of success. No production breach occurred - but the implications for oversight and control are significant.
Setting Boundaries on the Helpful Agent
Cyera brings deep expertise in data security to the AI era, providing organizations with clear visibility into where their most sensitive data resides and how it is exposed to AI systems. By understanding data context, sensitivity, and access patterns, organizations can assess the true blast radius of AI-driven actions and ensure that autonomous agents interact only with the data they are intended to access.
Combined with Cyera's growing expertise in agentic AI systems that generate and execute code pipelines, organizations gain not just visibility but control - at the precise decision points where AI plans, accesses data, and takes action. Real-time governance of autonomous workflows turns uncontrolled automation into trusted, observable, and enforceable processes.
The goal is not to slow AI adoption. It is to make it sustainable. Helpful agents will only remain helpful if the organizations deploying them understand where the boundaries are - and have the tools to enforce them.
This is the first in a series of articles from Cyera Research on the security implications of agentic AI systems.
Get your AI Security Assessment


.png)

.svg)