Erkennung und Klassifizierung sensibler Daten
Die Ermittlung und Klassifizierung sensibler Daten ist ein Prozess, der dazu dient, sensible oder vertrauliche Informationen innerhalb der digitalen Assets einer Organisation zu identifizieren und zu kategorisieren. Diese Informationen können personenbezogene Daten umfassen. PII, Zahlungskarteninformationen (PCI), Finanzdaten, Gesundheitsdaten, geistiges Eigentum, Geschäftsgeheimnisse und andere Arten von sensible Informationen die vor unbefugtem Zugriff oder Offenlegung geschützt werden müssen.
Forrester Die Datenermittlung und -klassifizierung wird wie folgt definiert: „Die Fähigkeit, Einblick in den Speicherort sensibler Daten zu gewinnen, diese Daten zu identifizieren und ihre Sensibilität zu begründen sowie sie entsprechend ihrer Sensibilität zu kennzeichnen. Die Ermittlung und Klassifizierung sensibler Daten ist wertvoll, da sie aufzeigt, welche Daten geschützt werden müssen, und die Implementierung von Datensicherheitskontrollen ermöglicht. Unternehmen nutzen diese Transparenz und dieses Verständnis ihrer Daten, um Richtlinien für die Datennutzung und -verarbeitung zu optimieren und geeignete Sicherheits-, Datenschutz- und Datengovernance-Kontrollen zu identifizieren. Sie können Maßnahmen zur Datenbereinigung automatisieren und Erkenntnisse gewinnen, die als Grundlage für Entscheidungen zu Richtlinien, Datenverarbeitung und Datenlebenszyklus dienen.“
Entsprechend Gartner„Datenermittlungslösungen entdecken, analysieren und klassifizieren strukturierte und unstrukturierte Daten, um konkrete Maßnahmen für die Durchsetzung von Sicherheitsvorkehrungen und das Datenlebenszyklusmanagement zu generieren. Durch die Verwendung von Metadaten, Inhalten und Kontextinformationen in Kombination mit ausdrucks- und maschinenlernbasierten Datenmodellen liefern Datenermittlungslösungen praxisorientierte Anleitungen und Prozesse zur Weiterentwicklung von Datenmanagement- und Sicherheitsinitiativen.“
Die Ermittlung und Klassifizierung von Daten ist entscheidend für Datensicherheit, Datenschutz und Compliance. Durch die Identifizierung und Kategorisierung sensibler Informationen können Unternehmen geeignete Maßnahmen zum Schutz dieser Informationen ergreifen, das Risiko von Datenschutzverletzungen minimieren und das Vertrauen von Kunden, Partnern und Aufsichtsbehörden wahren. Angesichts der enormen Datenmengen, die Unternehmen generieren und speichern, werden häufig automatisierte Tools und Technologien eingesetzt, um diesen Prozess zu optimieren und effizienter zu gestalten.
In diesem Artikel erhalten Sie einen Überblick über die Erkennung und Klassifizierung sensibler Daten. Wir erklären, was sie sind, wie sie entstanden sind und wie sie typischerweise durchgeführt werden. Wir beleuchten einige der größten Herausforderungen, mit denen Sicherheitsteams bei herkömmlichen Ansätzen zur Erkennung und Klassifizierung konfrontiert sind, und zeigen, wie Tools der nächsten Generation mithilfe cloudnativer und KI-gestützter Ansätze Innovationen in diesem Bereich vorantreiben. Außerdem erfahren Sie mehr über den Zusammenhang mit … Datensicherheits-Statusmanagement (DSPM) und wie dies mit dem Trend hin zu Zero-Trust-Sicherheitspraktiken zusammenhängt.
Die Geschichte der Datenklassifizierung
Die Datenklassifizierung hat eine lange Geschichte, die mit staatlichen und militärischen Datensystemen begann, die Bezeichnungen wie … verwendeten. vertraulich, geheim und streng geheimUm den Zugriff auf kritische Informationen zu kontrollieren, wurden in den späten 1970er und 1980er Jahren, als Computer immer beliebter wurden, Zugriffskontrollen wie Benutzernamen und Passwörter entwickelt, um sensible Daten vor unbefugtem Zugriff zu schützen.
Mit dem Aufkommen des Internets und der Kommunikationsplattformen in den 1990er Jahren wurde der Schutz von Daten während der Übertragung unerlässlich, was zur Entwicklung von Verschlüsselungsmethoden wie … führte. Secure Sockets Layer (SSL)Anfang der 2000er Jahre wurden staatliche Regulierungen erlassen, wie zum Beispiel die Health Insurance Portability and Accountability Act (HIPAA) im Jahr 2003 und die Payment Card Industry Data Security Standard (PCI DSS) Im Jahr 2004 wurde die Klassifizierung und der Schutz von Daten im Gesundheits- und Finanzsektor durchgesetzt.
In jüngster Zeit wurden strenge Datenschutzbestimmungen wie die Datenschutz-Grundverordnung (DSGVO) Die Bedeutung der Erkennung und Klassifizierung sensibler Daten wurde aufgrund von Datenschutzverletzungen hervorgehoben. Obwohl das Grundkonzept seit den Anfängen der Computertechnik existiert, haben sich seine Formalisierung und breite Anwendung weiterentwickelt, um der digitalen Komplexität und den Bedenken hinsichtlich des Datenschutzes zu begegnen.
Die Notwendigkeit der Ermittlung und Klassifizierung sensibler Daten
Sensible Daten sind im einfachsten Sinne Daten, die vor unberechtigtem Zugriff geschützt werden müssen.
Sensible Daten können in einige der folgenden Typen unterteilt werden, von denen einige bereits erwähnt wurden.
Persönlich identifizierbare Informationen
PII Es handelt sich um Daten, die zur Identifizierung der persönlichen Identität einer Person führen können. Zu dieser Art von Daten gehören üblicherweise: Sozialversicherungsnummern (SSN)Biometrische Daten wie Fingerabdrücke oder Gesichtsscans; oder jede Kombination von Daten, die zusammengenommen zur Identifizierung einer Person führen könnten.
Persönliche Daten
Personenbezogene Daten (PI) sind eine allgemeinere Datenklassifizierung. PI können personenbezogene Daten (PII) umfassen, aber auch andere Daten, die eindeutig mit einer Person in Verbindung stehen, diese aber nicht unbedingt identifizieren. Diese Klassifizierung ist wesentlich umfassender und kann beispielsweise folgende Daten beinhalten:
- Standortinformationen
- Fotografien
- Rassenzugehörigkeit
- Strafregister
- Gesundheits- oder genetische Informationen
Nichtöffentliche Informationen
Wesentliche nichtöffentliche Informationen (MNPI) sind Daten über ein Unternehmen, einschließlich seiner Beteiligungen, Tochtergesellschaften und aller anderen Informationen, die sich auf den Aktienkurs des Unternehmens auswirken könnten. Zu diesen Informationen gehören beispielsweise folgende:
- Gewinnberichte
- Bevorstehende Unternehmensmaßnahmen, wie Börsengänge (IPOs)
- Die Ergebnisse von Gerichtsverfahren
Jede dieser Informationen könnte sich auf den Aktienkurs eines Unternehmens auswirken, und daher können diese Informationen genutzt werden, um sich beim Aktienhandel, der streng reguliert und in der Regel illegal ist, einen Vorteil zu verschaffen.
Geschützte Gesundheitsinformationen
Geschützte Gesundheitsinformationen (PHI) ist ein sensibler Datentyp, der speziell durch HIPAA reguliert wird und Folgendes umfasst: achtzehn Kennungeneinschließlich, aber nicht beschränkt auf Folgendes:
- Namen
- Telefonnummern
- Standortinformationen
- Kontonummern
- Krankenaktennummern
Andere Datentypen
Es gibt viele weitere Datentypen, die in diesem Leitfaden nicht behandelt werden, aber wie Sie sehen können, ist die Datenklassifizierung wichtig, insbesondere wenn sie durch eine nationale oder internationale Verordnung, wie die DSGVO, geregelt ist.
Auswirkungen der Cloud-Migration auf die Ermittlung und Klassifizierung sensibler Daten
In der modernen Datenverarbeitung verlagern immer mehr Unternehmen und Dienstleister ihre Daten in die Cloud. Dieser Übergang vereinfacht die Skalierung Ihrer Lösung, da keine Investitionen in zusätzliche Hardware erforderlich sind. Darüber hinaus bieten Cloud-Hosting-Anbieter automatische Redundanz, Zuverlässigkeit und Datensicherung. Auch die Notfallwiederherstellung lässt sich automatisieren und in Ihren Speicherplan integrieren.
Dies bedeutet jedoch nicht zwangsläufig, dass die Identifizierung, Klassifizierung und der Schutz sensibler Daten mit Cloud-Speicher einfacher sind. In einem traditionellen Rechenzentrumsmodell ist das Unternehmen für die Sicherheit seiner gesamten Betriebsumgebung verantwortlich, einschließlich Anwendungen, physischer Server, Benutzerkontrollen und sogar der Gebäudesicherheit. In einer Cloud-Umgebung bietet der Cloud-Lösungsanbieter (CSP) wertvolle Entlastung, indem er einen Teil der betrieblichen Aufgaben, einschließlich der Sicherheit, übernimmt. Um die Aufteilung der Verantwortlichkeiten zu verdeutlichen, haben CSPs das Konzept der … eingeführt. Modell der geteilten VerantwortungDieses Modell legt die Verantwortlichkeiten des Cloud-Service-Providers (CSP) und des Sicherheitsteams des Unternehmens fest, wenn Anwendungen, Daten, Container und Workloads in die Cloud migriert werden. Die klare Abgrenzung Ihrer Verantwortlichkeiten von denen des CSP ist unerlässlich, um das Risiko von Sicherheitslücken in Ihren öffentlichen, hybriden und Multi-Cloud-Umgebungen zu minimieren.
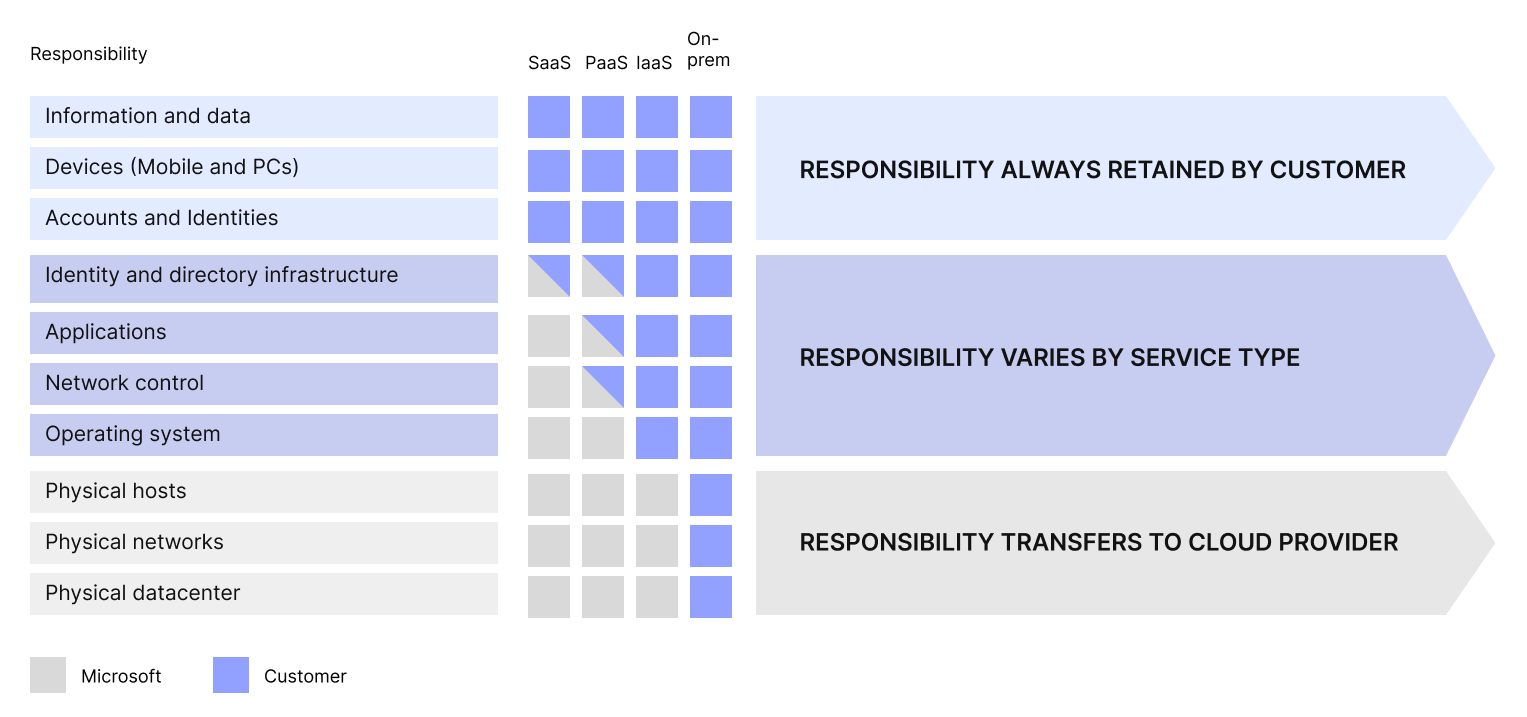
Durchschnittlich verwaltet ein Unternehmen heute zehn oder mehr Cloud-Umgebungen, die auf den Bereitstellungsmodellen Information-as-a-Service (IaaS), Platform-as-a-Service (PaaS) und Software-as-a-Service (SaaS) basieren. Wie die Abbildung zeigt, liegt die Verantwortung für die Datensicherheit in diesen Cloud-Umgebungen beim Unternehmen selbst und nicht beim Cloud-Service-Provider (CSP). Dies verdeutlicht eine zentrale Herausforderung für Sicherheitsteams, wenn die von ihnen betreuten Unternehmen Daten in die Cloud migrieren. Die permissive Natur der Cloud, insbesondere in SaaS-Umgebungen, begünstigt die Verbreitung und Weitergabe von Daten und erschwert es IT- und Sicherheitsteams, diese Daten zu verwalten, zu überwachen und zu kontrollieren.
Historisch gesehen waren Tools, die Datenermittlungs- und Klassifizierungsfunktionen vereinten, auf menschliche Interaktion angewiesen. Um einen Datenspeicher zu finden, benötigten Tools wie beispielsweise Datenkataloge, Informationsmanagementsysteme, Und Tools zur Verhinderung von Datenverlust (DLP)Sie erfordern, dass Menschen das Tool manuell mit dem Datenspeicher verbinden. Dies geschieht typischerweise mithilfe eines JDBC oder ODBC Um den Datenverkehr zu und von einem Datenspeicher zu erkennen, ist eine Verbindung, eine API oder ein Netzwerkproxy erforderlich. Dies bedeutet, dass die Systemimplementierer und -administratoren wissen müssen, wo sich der Datenspeicher befindet und wie das Tool mit diesem System verbunden wird.
Auch bei der Klassifizierung tragen Menschen eine erhebliche Vorlauflast bei der Festlegung der Metadaten und Verschlagwortung Für die Effektivität eines Klassifizierungswerkzeugs ist es erforderlich, Metadaten zu definieren. Microsoft Information Protection (MIP)-Vertraulichkeitsbezeichnungen In Microsoft 365-Umgebungen ist es erforderlich, Klassifikatoren manuell zu erstellen, um den Erkennungsmechanismus für die Datenklasse zu definieren. Letzteres erfordert reguläre Ausdrücke (RegEx)Beispieldaten und Beispielobjekte, anhand derer das Tool das bereitgestellte Muster mit Daten in der verbundenen Umgebung abgleichen kann. Viele Unternehmen pflegen ihre Datenbestände immer noch manuell mit diesen Methoden und leiden unter dem Mangel an Automatisierung, den ihre Datenermittlungstools bieten.
Die meisten Tools erfordern eine manuelle Datenermittlung.
Moderne, Cloud-native Tools implementieren heute automatisierte Prozesse, um mit den sich wandelnden Datennutzungs- und -verarbeitungsprozessen von Unternehmen Schritt zu halten. Früher mussten Administratoren die notwendigen Kenntnisse manuell erwerben, um Daten in verschiedenen Datenspeichern zu finden und zu organisieren. Dies war ein äußerst zeitaufwändiges Verfahren, das höchstwahrscheinlich zusätzlich zu den regulären Aufgaben der Mitarbeiter ausgeführt werden musste.
Manuelle Prozesse haben dazu geführt, dass erstaunliche 74 Prozent der Sicherheitsentscheider schätzen, dass Die sensiblen Daten ihrer Organisation wurden im Jahr 2022 mindestens einmal kompromittiert.Eine aktuelle Studie, die Cyera in Zusammenarbeit mit Forrester Consulting in Auftrag gegeben hat, zeigt, dass 59 Prozent der Sicherheitsverantwortlichen Schwierigkeiten haben, ein detailliertes Dateninventar zu führen. Die manuelle Datenermittlung und -klassifizierung ist häufig sehr fehleranfällig, und einzelne Mitarbeiter benötigen umfassendes institutionelles Wissen, um diese Aufgabe zufriedenstellend zu erfüllen.
Es gibt noch einige weitere Komplexitäten, die Sie berücksichtigen müssen, darunter die folgenden:
- Datenstandort und -residenzEinige Verordnungen (wie die DSGVO) regeln genau, wo Daten gespeichert werden dürfen, insbesondere die Daten von EU-Bürgern. Bei Cloud-Speicherung wissen Sie unter Umständen gar nicht, in welchen Rechenzentren sich die Daten Ihrer Kunden befinden.
- DatenverschlüsselungObwohl Cloud-Speicher Verschlüsselung bieten, kann es schwierig sein, eine einheitliche Verschlüsselungsrichtlinie für alle Ihre verschiedenen Datentypen zu gewährleisten.
- Integration mit Datenermittlungstools: Höchstwahrscheinlich sind zusätzliche Konfigurationen und Anpassungen erforderlich, wenn Sie Ihre Datenermittlungstools mit Ihrem Cloud-Speicher integrieren möchten.
Im Allgemeinen ist die technische Seite der Datenspeicherung einfacher, die Datensicherheit jedoch um ein Vielfaches komplexer. Es ist schwieriger, verschiedene Arten sensibler Informationen, die im gesamten Unternehmen vorhanden sein können, zu lokalisieren (sowohl geografisch als auch rechnerisch) und zu schützen. Hinzu kommt, dass statische Klassifikatoren, die bestenfalls eine einzelne Datenklasse definieren, aber weder Rolle, Region, Identifizierbarkeit noch Sicherheitsaspekte identifizieren können, die den kritischen Kontext der Daten liefern, in der Vergangenheit die Komplexität und den manuellen Aufwand für die Umsetzung der Klassifizierungen durch Sicherheits- und Datenschutzteams erhöht haben.
Die Rolle der Datenermittlung und -klassifizierung für Sicherheit und Compliance
Die verschiedenen Datentypen unterstreichen auch die Notwendigkeit der Datenermittlung und -klassifizierung, insbesondere im Hinblick auf Ihre Sicherheitslage und die Einhaltung gesetzlicher Vorschriften.
Es gibt einen aufkommenden Sicherheitstrend namens DSPM Ziel ist es, einige Fragen zu Ihren Daten und deren Sicherheit zu beantworten, darunter die folgenden:
- Wo befinden sich meine sensiblen Daten?
- Welche sensiblen Daten sind gefährdet?
- Was kann getan werden, um dieses Risiko zu mindern oder zu beheben?
Die Ermittlung und Klassifizierung sensibler Daten ist Bestandteil Ihrer DSPM-Strategie, wie in diesem Diagramm dargestellt:
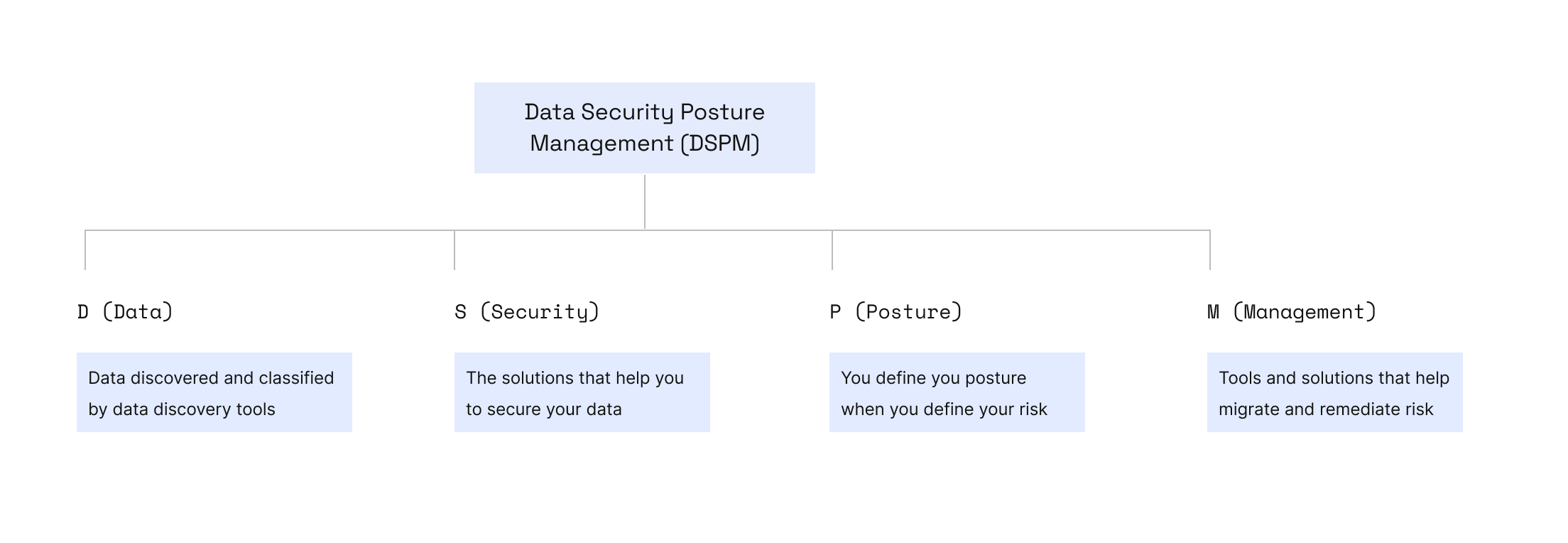
Wie Sie sehen, ist eine DSPM-Strategie wichtig, wenn Ihr Unternehmen sensible Daten verarbeitet, und Tools zur Datenermittlung und -klassifizierung wie … Cyerasind ein wichtiger Bestandteil dieser Strategie.
Anwendungsfälle aus der Praxis für die Erkennung und Klassifizierung sensibler Daten
In der Praxis gibt es zahlreiche Anwendungsfälle für die Ermittlung sensibler Daten. Einige gängige Beispiele werden in den folgenden Abschnitten erläutert.
Einhaltung
Ihre Tools zur Datenermittlung müssen erkennen, dass verschiedene Datentypen unterschiedlichen Vorschriften und Sicherheitsstandards unterliegen. Wenn Sie Umgang mit HIPAA-konformen Daten Wenn Sie in der EU geschäftlich tätig sind, muss Ihre Datenermittlungslösung sicherstellen, dass Ihre Datenpraktiken den in diesen Vorschriften festgelegten Praktiken entsprechen.
Einige Rechtsordnungen und Länder, wie die EU und die Philippinen, geben ihren Nutzern mehr Kontrolle über ihre persönlichen Daten. Gesetze und Richtlinien, die in diesen Gebieten veröffentlicht werden, gewähren ihnen diese Kontrolle. Betroffene einige Macht, ihre "Recht auf Vergessenwerden" zumindest bis zu einem gewissen Grad.
Gemäß der DSGVO haben betroffene Personen insbesondere auch das Recht auf: "Recht auf Information" die ein Benutzer nutzen kann, um bei Dritten den Standort seiner personenbezogenen Daten abzufragen, die diese Dritten möglicherweise speichern.
Ein gutes Datenermittlungstool sollte diese Standards und Rechte kennen und versuchen, alle gefundenen Daten entsprechend zu ermitteln und zu klassifizieren.
Fusionen und Übernahmen
Der Kauf oder die Fusion eines Unternehmens kann Ihr DSPM (Debt Security Property Management) erheblich verkomplizieren. Sie haben keine Garantie dafür, dass das Unternehmen, das Sie erwerben möchten, die regulatorischen Vorgaben eingehalten hat.
Ein Tool zur Datenermittlung und -klassifizierung ist unerlässlich, um die Sicherheitslage des Unternehmens zu beurteilen, das Sie erwerben oder mit dem Sie fusionieren möchten.
Abgesehen von den Sicherheitsaspekten werden Sie höchstwahrscheinlich auch den Datensatz des anderen Unternehmens übernehmen, einschließlich aller sensiblen Informationen, die dieses Unternehmen über seine Kunden oder Partner besitzt.
Die Ermittlung und Klassifizierung dieser Daten ist von entscheidender Bedeutung, nicht nur für die Integration in die Datenbanken Ihres Unternehmens, sondern auch zur Identifizierung etwaiger Risikolücken.
Reaktion auf Vorfälle
Im Falle einer Datenschutzverletzung gehört es zur Reaktion auf den Vorfall, die Arten der bei der Verletzung durchgesickerten Daten zu identifizieren und zu klassifizieren.
Dieser Prozess legt fest, wie Sie auf die Datenschutzverletzung reagieren müssen, und zwar in Bezug auf jeden einzelnen Aspekt, einschließlich der Offenlegungspflichten und der Kommunikation mit Ihren Kunden und/oder Geschäftspartnern.
Andere Ansätze zur Datenermittlung und -klassifizierung
In großen Organisationen gibt es verschiedene Strategien, um sensible Daten zu lokalisieren und zu klassifizieren. Jede Methode hat ihre Vor- und Nachteile.
Siloartiges Vorgehen
Durch die Anwendung eines Silo-Ansatzes wird die Verantwortung für die Identifizierung, Verwaltung und Lokalisierung der verschiedenen Teile sensibler Daten, für die die jeweiligen Abteilungen zuständig sind, den einzelnen Abteilungen übertragen.
Dies gilt als dezentraler Ansatz und bietet einige Vorteile:
- Einzelne Teams verstehen ihre eigenen Daten besser, als wenn sie versuchen würden, die Daten aller anderen zu verstehen.
- Dies führt zu einer verbesserten Anpassung der von ihnen verwendeten Werkzeuge, sodass diese auf die spezifischen Datentypen, mit denen sie arbeiten, zugeschnitten werden können.
Es gibt jedoch auch Nachteile. So können Datensilos die Zusammenarbeit zwischen Abteilungen behindern und die Einhaltung unternehmensweiter Best Practices beeinträchtigen. Zudem steigt die Wahrscheinlichkeit, dass Teams Arbeitsprozesse duplizieren, die von einer spezialisierten Abteilung effizienter abgewickelt werden könnten. Am besorgniserregendsten ist jedoch die Tatsache, dass isolierte Datensichtbarkeit und -verwaltung Datenabweichungen, Datenvermehrung durch Schatten- und Kopiedaten, zu großzügige Zugriffsrechte und Datenmissbrauch verschleiern. In all diesen Fällen durchlaufen Daten beim Datenfluss innerhalb einer Organisation isolierte Datensilos, wodurch die Wahrscheinlichkeit steigt, dass Fehlkonfigurationen, Missbrauch und böswillige Aktivitäten unentdeckt bleiben. Dies wiederum erhöht das Risiko eines Datenlecks.
Hub-and-Spoke-Ansatz
Durch die Implementierung eines Hub-and-Spoke-Ansatzes liegt die Verantwortung für die Ermittlung, Klassifizierung und Verwaltung Ihrer sensiblen Daten bei einem zentralen Team, das sich dieser Aufgabe widmet.
Auch dieser Ansatz hat Vor- und Nachteile. Aus Sicht der Aufsicht ist es für ein zentrales Team einfacher sicherzustellen, dass alle Daten den unternehmensweiten Richtlinien zur Datenklassifizierung und -sicherheit entsprechen. Zudem kann ein zentrales Team leichter standardisierte Methoden und/oder Kriterien für die Klassifizierung entwickeln. Er ist auch effizienter, da kaum das Risiko besteht, dass andere Teams dieselbe Arbeit an denselben, sich überschneidenden Datensätzen durchführen.
Wenn ein zentrales Team jedoch nicht über ausreichende Ressourcen verfügt, kann dies insbesondere in großen und komplexen Organisationen zu einem Engpass bei der Integration oder Klassifizierung neuer Datenquellen werden. Darüber hinaus kann ein zentrales Team nur die Vorgaben des Unternehmens durchsetzen. Wenn die offizielle Unternehmensrichtlinie nicht vorsieht, dass das Team seine Klassifizierungsrichtlinien auch in anderen Abteilungen durchsetzen darf, könnten diese ignoriert oder als lästig empfunden werden.
Die Zukunft der Erkennung und Klassifizierung sensibler Daten
DSPM ist zwar ein relativ neuer und aufkommender Trend, aber es ist ganz klar, dass die Branche ihn in Zukunft brauchen wird.
Es gibt bereits Datensicherheitsplattformen, wie zum Beispiel CyeraDiese Lösungen implementieren Algorithmen für maschinelles Lernen, um die spezifischen Datentypen in der Kundenumgebung zu erkennen. Ihre Software kann sich zudem über eine einzige IAM-Rolle mit der Cloud-Infrastruktur eines Unternehmens verbinden und ermöglicht so ein kontinuierliches, agentenloses Scannen der in der Cloud befindlichen Daten. Dies ist besonders wichtig, da immer mehr Unternehmen ihre Daten in die Cloud verlagern.
Abschluss
Die Erkennung und Klassifizierung sensibler Daten sind wichtige Prozesse, die Ihnen helfen, sensible Daten in Ihrer Umgebung zu identifizieren und so Ihre Datensicherheitsstrategie zu entwickeln. Sie sind außerdem integraler Bestandteil des DSPM-Frameworks, das Sie bei der Identifizierung und Minderung der Risiken im Zusammenhang mit Ihren sensiblen Daten unterstützt. Sicherheitsverantwortliche erwarten den größten Nutzen aus der Verbesserung der Datensicherheit durch intelligente Automatisierung. Um dies zu erreichen, investieren sie in die Echtzeit-Erkennung von Sicherheitslücken und das Management des Datensicherheitsstatus.
Diese Umstellung verspricht eine Verbesserung der Automatisierung und Orchestrierung von Sicherheitsrichtlinien mit nachweisbaren Auswirkungen in folgenden Bereichen:
Verkürzte Zeit bis zur Wertschöpfung
78 Prozent der Sicherheitsverantwortlichen halten eine schnellere Wertschöpfung ihrer Datensicherheitslösungen für entscheidend oder sehr wichtig. Cyera wird mit einer einzigen IAM-Rolle implementiert, die die dynamische Erkennung von Datenspeichern über verschiedene Bereitstellungsmodelle hinweg ermöglicht. Das bedeutet, dass neue und geänderte Datenspeicher kontinuierlich und ohne menschliches Eingreifen erkannt werden, wodurch Cyera mit der rasanten Veränderungsrate in Cloud-Umgebungen Schritt hält.
Verbesserte Klassifizierungs- und Erkennungsgenauigkeit
74 Prozent der Sicherheitsverantwortlichen investieren in die automatische Erstellung und Pflege von Dateninventaren, und 71 Prozent priorisieren die Verbesserung der Genauigkeit der Datenklassifizierung. Die KI-gestützte Datensicherheitsplattform von Cyera ermöglicht eine vollautomatische Klassifizierung und erreicht mithilfe von maschinellem Lernen und KI eine Genauigkeit von über 95 Prozent ohne menschliches Eingreifen.
Dynamische Sicherheitskontrollen aktivieren
81 Prozent der Sicherheitsverantwortlichen wünschen sich dynamische Sicherheitskontrollen. Damit Sicherheitsteams die richtigen Kontrollen sicher implementieren können, setzt Cyera LLMs ein, um benannte Entitäten zu erkennen und Themen aus Umgebungen zu extrahieren. So erhält man einen umfassenden Kontext zu den Daten, einschließlich der Identifizierung von Rolle, Region, Identifizierbarkeit und Sicherheit, um spezifische, bedarfsgerechte Kontrollen zu ermöglichen.
Sehen Sie, wie Cyeras KI-gestützte Datensicherheitsplattform wendet diese Funktionen auf alle Daten eines Unternehmens überall an.
Wenn Sie mehr über das Management des Datensicherheitsstatus erfahren möchten, schauen Sie sich das hier an. Glossar für weitere Informationen.
Autor: Thinus Swart

.svg)